
Если файл robots.txt возвращает ошибку 5xx, то Google не будет сканировать сайт
- Stats: 727 1
- Author: admin
- Category: SEO, Просування сайту. Копірайт, Статті
- Comments: Комментариев нет

Если Googlebot не может получить доступ к файлу robots.txt из-за ошибки 5xx, то он не будет сканировать сайт. Об этом заявил один из сотрудников команды поиска на Google
Webmaster Conference, которая прошла в начале этой недели в штаб-квартире компании GooglePlex.
Согласно Google, при сканировании robots.txt ошибка 5xx возвращается в 5% случаев, в 69% — краулер получает код ответа сервера 200 или 404, а в 26% — файл robots.txt совсем недоступен.
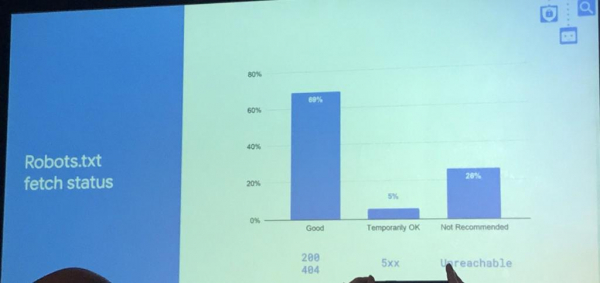
После выхода материала Search Engine Land, в котором изначально говорилось о том, что Google не будет сканировать сайт, если файл robots.txt существует, но недоступен (т.е. в 26% случаев), в Twitter начали активно обсуждать этот вопрос. Совместными усилиями западным специалистам удалось выяснить, что на самом деле речь шла о 5% случаев, когда сервер возвращает ошибку 5xx.
Соответствующая поправка была внесена и в статью Search Engine Land.
Если файла robots.txt нет, то Google будет считать, что никаких запретов на сканирование нет:
I was in the room, this is what was said... Indeed, 404 = crawl anywhere. If you didnt have a robots.txt file, Google would still crawl you, this is that.
5xx's are considered a crawl block.— Martin MacDonald (@searchmartin) November 5, 2019
Сотрудник Google Гэри
Илш ответил, что с WP обычно нет проблем, но он ещё дополнительно проверит.
WP is usually fine i think as it doesn't control network afaik, and someone must've misconfigured something real bad if the robotstxt comes back with 5xx. That said, I'll run an analysis and then i can say for sure
— Gary "鯨理/경리" Illyes (@methode) November 6, 2019









Отправить ответ