Готовый robots.txt под WordPress
- Stats: 2057 2
- Author: admin
- Category: CMS WordPress
- Comments: Комментариев нет

В этой статье пример оптимального, на наш взгляд, кода для файла robots.txt под WordPress, который вы можете использовать в своих сайтах.
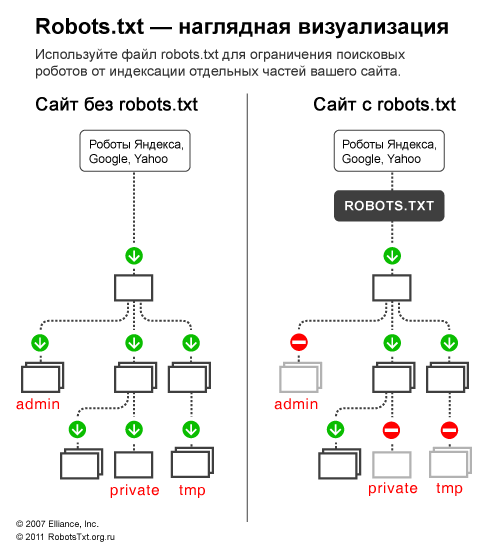
Для начала, вспомним зачем нужен robots.txt — файл robots.txt нужен исключительно для поисковых роботов, чтобы «сказать» им какие разделы/страницы сайта посещать, а какие посещать не нужно. Страницы, которые закрыты от посещения не будут попадать в индекс поисковиков (Yandex, Google и т.д.).
Вариант 1: оптимальный код robots.txt для WordPress
User-agent: *
Disallow: /cgi-bin # классика...
Disallow: /? # все параметры запроса на главной
Disallow: /wp- # все файлы WP: /wp-json/, /wp-includes, /wp-content/plugins
Disallow: *?s= # поиск
Disallow: *&s= # поиск
Disallow: /search # поиск
Disallow: /author/ # архив автора
Disallow: *?attachment_id= # страница вложения. Вообще-то на ней редирект...
Disallow: */trackback
Disallow: */feed # все фиды
Disallow: */embed # все встраивания
Disallow: */page/ # все виды пагинации
Allow: */uploads # открываем uploads
Allow: /*/*.js # внутри /wp- (/*/ - для приоритета)
Allow: /*/*.css # внутри /wp- (/*/ - для приоритета)
Allow: /wp-*.png # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.jpeg # картинки в плагинах, cache папке и т.д.
Allow: /wp-*.gif # картинки в плагинах, cache папке и т.д.
#Disallow: /wp/ # когда WP установлен в подкаталог wp
Host: www.site.ru
Sitemap: http://site.ru/sitemap.xml
Sitemap: http://site.ru/sitemap2.xml
# Версия кода: 1.0
# Не забудьте поменять <code>site.ru на ваш сайт.
Разбор кода:
В строке User-agent: * мы указываем, что все нижеприведенные правила будут работать для всех поисковых роботов *. Если нужно, чтобы эти правила работали только для одного, конкретного робота, то вместо * указываем имя робота (User-agent: Yandex, User-agent: Googlebot).
В строке Allow: */uploads мы намеренно разрешаем индексировать ссылки, в которых встречается /uploads. Это правило обязательно, т.к. выше мы запрещаем индексировать ссылки начинающихся с /wp-, а /wp- входит в /wp-content/uploads. Поэтому, чтобы перебить правило Disallow: /wp- нужна строчка Allow: */uploads, ведь по ссылкам типа /wp-content/uploads/... у нас могут лежать картинки, которые должны индексироваться, так же там могут лежать какие-то загруженные файлы, которые незачем скрывать. Allow: может быть «до» или «после» Disallow:.
Остальные строчки запрещают роботам «ходить» по ссылкам, которые начинаются с:
Disallow: /cgi-bin — закрывает каталог скриптов на сервере
Disallow: /feed — закрывает RSS фид блога
Disallow: /trackback — закрывает уведомления
Disallow: ?s= или Disallow: *?s= — закрыавет страницы поиска
Disallow: */page/ — закрывает все виды пагинации
Правило Sitemap: http://site.ru/sitemap.xml указывает роботу на файл с картой сайта в формате XML. Если у вас на сайте есть такой файл, то пропишите полный путь к нему. Таких файлов может быть несколько, тогда указываем путь к каждому отдельно.
В строке Host: site.ru мы указываем главное зеркало сайта. Если у сайта существуют зеркала (копии сайта на других доменах), то чтобы Яндекс индексировал всех их одинаково, нужно указывать главное зеркало. Директива Host: понимает только Яндекс, Google не понимает! Если сайт работает под https протоколом, то его обязательно нужно указать в Host: Host: https://site.ru
Из документации Яндекса: «Host — независимая директива и работает в любом месте файла (межсекционная)». Поэтому её ставим наверх или в самый конец файла, через пустую строку.
Это важно: сортировка правил перед обработкой
Yandex и Google обрабатывает директивы Allow и Disallow не по порядку в котором они указаны, а сначала сортирует их от короткого правила к длинному, а затем обрабатывает последнее подходящее правило:
User-agent: *
Allow: */uploads
Disallow: /wp-
будет прочитана как:
User-agent: *
Disallow: /wp-
Allow: */uploads
Таким образом, если проверяется ссылка вида: /wp-content/uploads/file.jpg, правило Disallow: /wp- ссылку запретит, а следующее правило Allow: */uploads её разрешит и ссылка будет доступна для сканирования.
Чтобы быстро понять и применять особенность сортировки, запомните такое правило: «чем длиннее правило в robots.txt, тем больший приоритет оно имеет. Если длина правил одинаковая, то приоритет отдается директиве Allow.»
Вариант 2: стандартный robots.txt для WordPress
Не знаю кто как, а я за первый вариант! Потому что он логичнее — не надо полностью дублировать секцию ради того, чтобы указать директиву Host для Яндекса, которая является межсекционной (понимается роботом в любом месте шаблона, без указания к какому роботу она относится). Что касается нестандартной директивы Allow, то она работает для Яндекса и Гугла и если она не откроет папку uploads для других роботов, которые её не понимают, то в 99% ничего опасного это за собой не повлечет. Я пока не заметил что первый robots работает не так как нужно.
Вышеприведенный код немного не корректный.
1. Некоторые роботы (не Яндекса и Гугла) — не понимают более 2 директив: User-agent: и Disallow:;
2. Директиву Яндекса Host: нужно использовать после Disallow:, потому что некоторые роботы (не Яндекса и Гугла), могут не понять её и вообще забраковать robots.txt. Cамому же Яндексу, судя по документации, абсолютно все равно где и как использовать Host:, хоть вообще создавай robots.txt с одной только строчкой Host: www.site.ru, для того, чтобы склеить все зеркала сайта;
3. Sitemap: межсекционная директива для Яндекса и Google и видимо для многих других роботов тоже, поэтому её пишем в конце через пустую строку и она будет работать для всех роботов сразу.
На основе этих поправок, корректный код должен выглядеть так:
User-agent: Yandex
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/themes
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /comments
Disallow: */trackback
Disallow: */embed
Disallow: */feed
Disallow: /cgi-bin
Disallow: *?s=
Host: site.ru
User-agent: *
Disallow: /wp-admin
Disallow: /wp-includes
Disallow: /wp-content/plugins
Disallow: /wp-content/themes
Disallow: /wp-login.php
Disallow: /wp-register.php
Disallow: /comments
Disallow: */trackback
Disallow: */embed
Disallow: */feed
Disallow: /cgi-bin
Disallow: *?s=
Sitemap: http://site.ru/sitemap.xml
Дописываем под себя
Если вам нужно запретить еще какие-либо страницы или группы страниц, можете внизу добавить правило (директиву) Disallow:. Например, нам нужно закрыть от индексации все записи в категории news, тогда перед Sitemap: добавляем правило:
Disallow: /news
Оно запретить роботам ходить по подобным ссылками:
http://site.ru**/news**
http://site.ru**/news**/drugoe-nazvanie/
Если нужно закрыть любые вхождения /news, то пишем:
Disallow: */news
Закроет:
http://site.ru**/news**
http://site.ru**/news**/drugoe-nazvanie/
http://site.ru/category**/news**letter-nazvanie.html
Проверка robots.txt
Проверить правильно ли работают прописанные правила можно по следующим ссылкам:
Яндекс: http://webmaster.yandex.ru/robots.xml.
В Google это делается в Search console. Нужна авторизация и наличия сайта в панели веб-мастера...
Сервис для создания файла robots.txt: http://pr-cy.ru/robots/
Сервис для создания и проверки robots.txt: https://seolib.ru/tools/generate/robots/
Вот и все, если Вы хотите «поблагодарить» наше IT сообщество — у вас есть такая возможность: справа есть варианты для пожертвований на развитие портала. Или поделитесь статьей в ваших соц.сетях через сервис ниже.








Отправить ответ